
Welcome to the DP-700 Official Practice Test – Part 1.
In this part, I have given my detailed explanations of the 10 official questions from Microsoft. Unlike on the Microsoft website, the explanations include screenshots to help you prepare for the DP-700 exam.
That said, these tests are very simple, and they should only be used to brush up on the basics. The real exam would rarely be this easy. To get more rigorous practice and even in-depth knowledge, check out my practice tests (click the button below).
Once done, check out the DP-700 questions Part -2 and the accompanying DP-700 Practice Test video.
1] Your organization is transitioning to a data mesh architecture using Microsoft Fabric. You are responsible for organizing data into domains.
You need to configure settings for independent management of rules and restrictions by each business unit.
What should you do?
A. Assign workspaces to multiple domains.
B. Configure domain-specific sensitivity labels.
C. Create workspaces with shared governance settings.
D. Delegate tenant-level settings to domains.
A data mesh is a decentralized data architecture that structures data by business domains like marketing or sales. Microsoft Fabric supports data mesh by grouping data into domains and workspaces, enabling each department to manage and govern its data according to its specific needs.

https://learn.microsoft.com/en-us/fabric/governance/domains#introduction
To transition to a data mesh architecture, we configure settings for independent domains or business units. In Microsoft Fabric, you can find these settings under Admin portal -> Tenant settings.

However, these settings are at the tenant level. To allow independent business units to configure these settings, you have to delegate the tenant settings to a domain and from the domain to a workspace where the items are managed. But do note that not all settings can be delegated this way.
Only some settings can be delegated, for example, Export reports as Word documents. In this setting, you can either delegate to domain admins or workspace admins.

Once the setting is delegated to domain admins, go to the domain, which typically has one or more workspaces assigned. In the domain settings, he can see the delegated setting, Export reports as Word documents. From domains, the setting can be further delegated to workspaces, allowing more granular control to workspace admins.

In the workspace, he can further configure the setting for all workspace users or specific users in a security group.

Reference Link: https://learn.microsoft.com/en-us/fabric/admin/delegate-settings
So, delegating tenant-level settings to a domain will help configure independent management of rules and restrictions by each business unit. Option D is the correct answer.
Option A is incorrect. Multiple workspaces can be associated with a domain, not vice-versa. So you cannot associate a workspace with multiple domains.

Option B is incorrect. While sensitivity labels can be part of governance, they do not provide the overall control needed for managing rules and restrictions by each domain or business unit.
Option C is incorrect. Shared governance contradicts the data mesh model, which emphasizes decentralized and domain-specific governance.
2] A company uses Microsoft Fabric for data engineering workflows and notices Spark jobs are slow due to suboptimal resource allocation.
You need to enhance Spark job efficiency by adjusting environment settings.
What action should be taken?
A. Enable dynamic allocation of executors.
B. Increase the number of partitions.
C. Set a fixed memory allocation for executors.
D. Set a fixed number of nodes.
If the number of executors (which perform the work) doesn’t match the amount of workload, Spark jobs run slowly due to suboptimal resource allocation. In that case, enabling the dynamic allocation of executors will automatically adjust the number of executors based on demand, improving resource utilization. You can enable this feature under capacity settings in the admin portal.

Option A is the correct answer.
Reference Link: https://learn.microsoft.com/en-us/fabric/data-engineering/spark-compute#dynamic-allocation
Option B is incorrect. Although partitioning improves parallelism, without addressing executor allocation, increasing partitions alone may not resolve the issue. It’s not the primary solution for resource allocation issues.
Options C and D are incorrect as they do not adapt to the demands of the job leading to either underutilization or insufficient resources.
3] Your organization uses Microsoft Fabric to manage data across departments.
You need to ensure each department can manage its data governance settings independently.
What should you do?
A. Assign workspaces to a single domain.
B. Consolidate all departments under one domain.
C. Delegate tenant-level settings to domains.
D. Implement centralized governance policies.
Each domain represents a business unit or department, like Finance, etc.. A domain can have multiple workspaces associated with it.

Well, this question is very similar to Question 1, where we concluded that if you want each department to manage its data governance settings independently, you need to delegate tenant-level governance controls (such as data policies, sensitivity labels, and data access rules) to each domain.. Option C is the correct answer.
Reference Link: https://learn.microsoft.com/en-us/fabric/governance/domains#introduction
https://learn.microsoft.com/en-us/fabric/admin/delegate-settings
Option A is incorrect. In Fabric, domains are logical groupings of workspaces that allow for department-specific governance, aligning with a data mesh architecture. Assigning all workspaces to one domain means centralizing control under a single business unit, which prevents independent governance for other departments. This contradicts the requirement of letting each department manage governance independently.
Option B is incorrect. Consolidating into one domain would again centralize governance, which is not appropriate when you want each department to handle its governance settings.
Option D is incorrect. Centralized governance policies involve Fabric admins setting policies across the entire tenant, applied to all workspaces and domains. Centralized governance is the opposite of what is required.
4] Your organization is implementing a data mesh architecture using Microsoft Fabric. The IT department needs to delegate governance controls to business units.
You need to configure settings for independent data management by business units.
Each correct answer presents part of the solution. Which three actions should you take?
A. Assign domain-specific sensitivity labels.
B. Assign workspaces to domains.
C. Delegate tenant settings to domains.
D. Enable domain-level sensitivity labels.
E. Implement row-level security.
F. Specify domain administrators.
We have already learnt what a data mesh architecture is from Question 1. In Fabric, workspaces are the containers for assets like datasets, pipelines, etc.. By assigning workspaces to domains, you’re logically grouping data by business units like Finance, Legal, etc. This is the first step in decentralized data ownership.

Option B is one of the correct answers.
To support independent governance, you must delegate tenant-level settings to domain admins. This allows business units to manage their own governance settings.

Option C is also a correct answer.
Instead of a central IT team managing all governance, a data mesh architecture promotes decentralized data governance, so each domain is responsible for managing its own data products. To make this work, each domain needs a designated person responsible for governance within that domain — this is why specifying domain Administrators is important.
Option F is the other correct answer.
Option A is incorrect. Sensitivity labels are defined in Microsoft Purview and cannot be directly scoped to domains. You can assign sensitivity labels to content, but not create domain-specific labels.
Reference Link: https://learn.microsoft.com/en-us/purview/create-sensitivity-labels#create-and-configure-sensitivity-labels
Option D is incorrect. Sensitivity labels are tenant-wide, and there is no direct feature to enable them per domain.
Option E is incorrect. Row-level security is related to data access, not governance.
5] Your organization uses Microsoft Fabric to manage data engineering tasks. The current setup includes a starter pool for Apache Spark jobs, but the team notices that some jobs require more compute resources than the starter pool can provide.
You need to optimize the workspace configuration to efficiently handle larger Spark jobs without significantly increasing session start times.
Each correct answer presents part of the solution. Which two actions should you take?
A. Create a custom Spark pool with autoscaling.
B. Disable the starter pool.
C. Enable dynamic allocation of executors.
D. Increase executor memory in the starter pool.
E. Increase the number of partitions in the Spark job.
In Fabric, Spark pools are clusters of computing resources that run Apache Spark workloads. There are two types of Spark pools: Starter pool (default, built-in, cannot be customized for the default workspace environment) and custom pool. You can view the starter pool in your workspace settings.
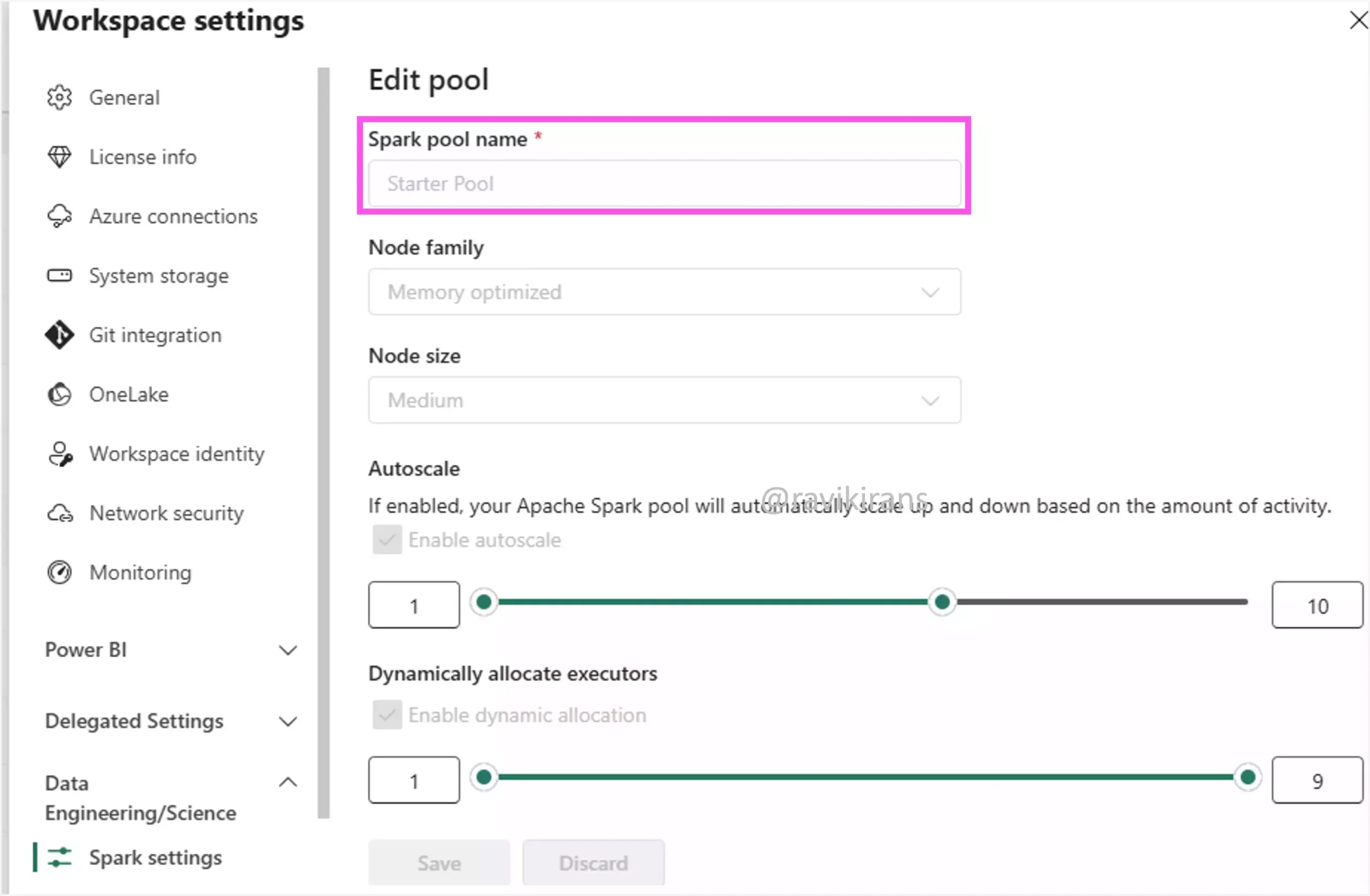
As you can see above, the starter pool has fixed configurations. You cannot increase executor memory in the starter pool. Option D is incorrect.
So, if you need more compute resources, create a custom Spark pool. Option A is one of the correct answers.

Option E is incorrect. Increasing the number of partitions can help increase parallelism. But it doesn’t solve the main problem, which is a lack of computing capacity.
Option B is incorrect. You will not get any benefits by disabling the starter pool.
Since the question asks for two actions, option C could be the other correct answer. Enabling dynamic allocation of executors adjusts the number of executors at runtime based on workload needs.

Note that enabling autoscaling and dynamic allocation of executors are different but complement each other. While autoscaling adds or removes Spark nodes (VMs) in the pool, dynamic allocation of executors adjusts the number of executors or processes used by a Spark job during execution.
6] Your organization uses Microsoft Fabric for data engineering and runs Spark jobs requiring efficient resource utilization.
You need to optimize resource management in the Microsoft Spark environment based on workload demands.
What should you do?
A. Enable autoscaling
B. Enable fixed resource allocation
C. Set a fixed number of executors
D. Set a fixed number of nodes
If you set a fixed number of resources, nodes, or executors, the resource utilization will not be efficient. Only if the nodes/executors adapt to the changing workload demands, can you ensure efficient resource utilization. Option A is the correct answer.
7] You are using Microsoft Fabric to manage data analytics solutions in your organization. Your team is responsible for optimizing Spark job performance in the workspace.
You need to configure the workspace settings to improve the efficiency of Spark job execution.
Each correct answer presents part of the solution. Which three actions should you perform?
A. Disable intelligent caching for Spark pools.
B. Enable autoscaling for Spark pools.
C. Enable intelligent caching for Spark pools.
D. Reserve maximum cores for jobs.
E. Select a different Spark runtime version.
F. Use high concurrency mode.
Well, intelligent caching is already enabled by default for all Spark pools, so this is not an action that we can take to optimize Spark job performance. Also, disabling caching is generally not recommended, as it can significantly degrade query performance. Options A and C are incorrect.
Reference Link: https://learn.microsoft.com/en-us/fabric/data-engineering/intelligent-cache#how-it-works
Option B is one of the correct answers. Autoscaling dynamically adjusts resources to match workload demands, boosting performance during peaks and saving costs during low usage. This results in job optimization.
Reserving maximum cores for jobs ensures that more compute resources (driver and executor cores) are available to handle large or complex workloads. Since the driver is the coordinator of a Spark job, increasing the driver cores improves the performance of jobs with many small tasks. Similarly, increasing the executor cores boosts parallelism.

Option D is also a correct answer since nothing is mentioned about optimizing the cost.
Option F is also correct. Enabling high concurrency helps you run multiple Spark notebooks or jobs concurrently using shared resources, reducing the start time for each session.

8] Your company implements a new analytics solution using Microsoft Fabric that requires frequent updates and testing before deployment to production.
You need to set up the deployment pipeline to enable backward deployment, deploying content from a later stage to a earlier stage in the pipeline..
Each correct answer presents part of the solution. Which three actions should you take?
A. Configure rules to maintain settings across stages.
B. Ensure the target stage is empty and has no workspace assigned to it.
C. Review deployment history.
D. Use incremental deployment for backward movement.
E. Use selective deployment for backward movement.
In Microsoft Fabric, a deployment pipeline consists of stages, typically Dev, Test, and Prod. And each stage is linked to a workspace.

Currently, backward deployment (from the Test to the Development stage) is possible only when the target stage is empty (i.e., has no contents). For example, below, since the WorkspaceB linked to the Development stage is not empty (has the artifact, pipelineB), the Deploy from Test stage is disabled.

Option B is one of the correct answers.
Reference Link: https://learn.microsoft.com/en-us/fabric/cicd/deployment-pipelines/get-started-with-deployment-pipelines#step-5—deploy-to-an-empty-stage
Honestly, the other two correct options are not evident, so let’s exclude the incorrect answers, which would lead us to the remaining correct answers.
Option D is incorrect. In the incremental deployment method, only the changed items are deployed from one stage to the next. Since incremental deployment requires comparing changes between two assigned and populated stages, it cannot be used in backward deployments, as backward deployments require an empty target stage.
Option E is incorrect. Selective deployment lets you choose which content to move from one stage to another. You can use selective deployment by selecting only a subset of the items while moving forward, for example, from dev to the test.

However, selective deployment doesn’t work if you deploy in reverse (i.e., for backward deployments). The Deploy button is disabled until you select all the items. Note, I have removed all the content from the Development stage, a prerequisite for backward deployment.

Now that we concluded options D and E are incorrect, and since we need to select three actions, the remaining options A and C must also be the correct answers.
9] An organization uses Microsoft Fabric for data analytics management.
You need to configure a deployment pipeline for content transition between development and production, allowing selective and backward deployment.
Each correct answer presents part of the solution. Which three actions should you take?
A. Assign workspaces to different environments.
B. Create a pipeline with multiple stages.
C. Deploy all content at once.
D. Enable full deployment.
E. Enable selective deployment.
F. Ensure target stage is empty.
As discussed in the previous question, the backward deployment is an all or nothing process. You can’t choose to move only certain reports or datasets; the entire workspace content should be moved.

So, I am not sure how the question is intended to be answered. If both selective and backward deployment are required together in a single scenario, then we know that it is not possible.
But to answer the question, let’s assume the possibility that both are required, but in separate scenarios. In that case, for either scenario, we need to create a deployment pipeline with multiple stages. Option B is one of the correct answers.
For backward deployment, the target stage has to be empty (as learnt in the previous question). Option F is also a correct answer.
And for selective deployment, you don’t deploy all the content. Option C is incorrect.
Well, there is no toggle button to choose either selective or full deployment. You choose either the entire workspace items or select only a subset of the items for deployment. So, options D and E don’t make sense.
Please let me know in the comments if you see this any differently.
10] Your organization uses Microsoft Fabric deployment pipelines to manage analytics solutions across Development, Test, and Production stages.
You need to restrict editing of pipeline settings to authorized users only.
What should you do?
A. Assign pipeline admin roles.
B. Configure workspace permissions.
C. Enable stage-level security.
D. Implement role-based access control.
To enable users to share, edit, and delete a deployment pipeline, assign pipeline admin roles. There is only one role, admin, which you can assign to users in deployment pipelines. Option A is the correct answer.

Note that these roles are granted and managed separately from the workspace roles. So to successfully deploy from one stage to another, you must be a pipeline admin and also have a relevant role for the workspace assigned to the linked stages. Option B is incorrect.
Reference Link: https://learn.microsoft.com/en-us/fabric/cicd/deployment-pipelines/understand-the-deployment-process?tabs=new-ui#permissions
Option C is incorrect. There is no security mechanism granting access to specific stages in deployment pipelines.
Option D is incorrect. Row-level security is exclusive to controlling access to data rows in a warehouse or SQL-based databases.
Reference Link: https://learn.microsoft.com/en-us/fabric/data-warehouse/row-level-security
Check out my DP-700 practice tests.
Follow Me to Receive Updates on the DP-700 Exam
Want to be notified as soon as I post? Subscribe to the RSS feed / leave your email address in the subscribe section. Share the article on your social networks with the links below so it can benefit others.


